As part of my (almost) daily drive to and from one of my clients I pass through the sub-sea Oslofjord tunnel (Oslofjordtunnelen). Now what has driving got to do with screen scraping and RSS, you say?
Hang on, I’m getting there.
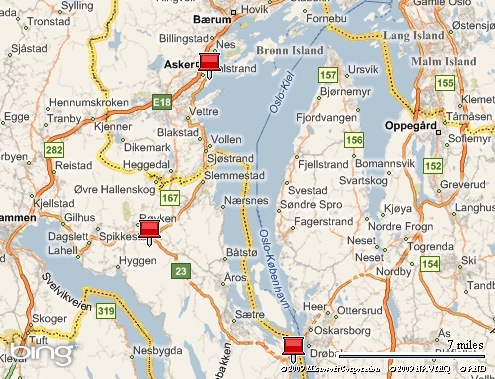
Below is a map extract that shows part of my route. The topmost pin is where I start out, the bottom-most pin is the Oslofjord tunnel. The pin in the middle is where, more often than not, a sign shows up stating that the tunnel is closed for maintenance. You can imagine my frustration when I’m forced to drive all the way back north to get around the Oslofjord!
To avoid that pain I set out to find a feed with traffic status updates and ended up at this page published by the Norwegian Public Roads Administration (NPRA). The page have regularly updated traffic information (all in Norwegian mind you) but to my frustration all as static web pages. No feed in sight!
At last here comes the screen scraping into play. You could write up your own scraper in any modern runtime these days. But being a good/lazy developer I know there are already quite good services out there that makes it a breeze setting up feeds with data scraped off of web pages. And lo and behold, I now burn a feed with the latest traffic updates!
So… basking in the glory of my genius for a couple of days I thought it a good idea to write up this blog post for the greater good of mankind. To make the story a bit shorter, what I discovered while rummaging around the NPRA site is that they indeed have great support for RSS!
Feeling a bit stupid I will now go and redirect my FeedBurner setup…and please let me know if there is a moral to this story.
Good night.

Hahaha! This is funny, since I followed this story as it happened last week. I hadn’t heard about them actually having a feed…
How come you didn’t find it when you where indeed looking very hard for it? It seems the NPRA still could make their content more discoverable…
The problem with finding the info in the first place, I guess, was that I didn’t search with the right words. So I ended up calling 1881 and they said “hey, go to 175.no” which redirects to http://www.vegvesen.no/trafikk/mobil.
And already there one moral to this story comes into play. Because, as a developer empowered with all these nifty (screen scraping and whatnot) tools at disposal, I thought “no rss? no problem, I can fix it myself”. Instead, what I really should’ve done was look at the url and say “hm, wonder what marvels are hidden at http://www.vegvesen.no/trafikk“.
The good part though, is that you actually looked for options in the end, not settling with NIH thught, and forcing your own code, now the feed have one more subscriber, and with any luck not gonna be deprecated just like that.
Hopefully this site: http://data.norge.no/ will be the ultimate catalog of services like this. (Yes, I know, it did not exist at time of your writing.)